Python文本分析——政府工作报告都说些啥?
好久没有更新博客了,正好最近对政府工作报告的内容产生了兴趣,那么这次就来研究一下。
对北方边陲某市某区2012-2019年的政府工作报告使用文本分析技术进行关键词提取,高频关键字,生成词云。
重点
对1954-2019年的国务院政府工作报告,按照全部年份以及以10年为间隔来计算,从这些工作报告中,也许能发现建国70年来的沧桑巨变。
关键词提取是文本分析领域一个很重要的部分,通过对文本提取的关键词可以窥探整个文本的主题思想,进一步应用于文本推荐或文本搜索。
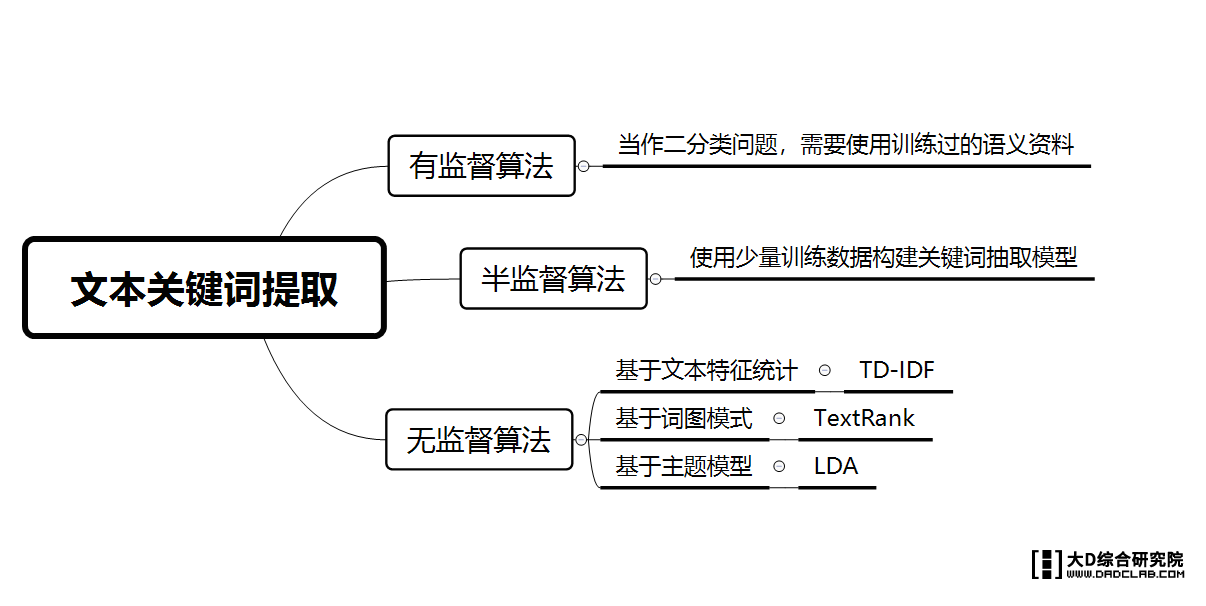
有监督算法:是将关键词抽取问题转化为判断每个候选关键词是否是关键词的二分法问题。需要使用一个标注了关键词的文档集合训练模型。标注训练集成本较高,所以无监督算法更为常用。
无监督算法:不需要进行人工标注训练集,利用某些方法发现文本中比较重要的词作为关键词,进行关键词提取。
词的重要性的衡量有多种方式:
-
基于文本特征统计——TD-IDF
-
基于词图模型——TextRank
-
基于主题模型——LDA
TF-IDF是关键词提取算法中最基本、最简单的方法。使用词频来衡量一个词在文章当中是否重要。重要的词往往在文章中出现的频率很高,但另一方面,不是出现次数越多的词就一定重要。在一篇中文文章当中,出现最多的词汇可能是“是”、“否”、“在”、“和”、“及”等常用词。
有些词会在各种文章中都频繁出现,那么这个词的重要性,就比在某一篇文章中重复出现频率高的词低。
于是,就给不常见的词以较大的权重,减少常见词的权重。
IDF(逆文档频率)就是指词的权重,TF指的是词频。那么,有如下公式:

一个词的IDF值的计算是根据语料库得出的,一个词在语料库中越常见,那么分母就越大,IDF就越小。
分母+1是为了保证词没有出现在文档中时分母为0。
最终TF-IDF的计算:
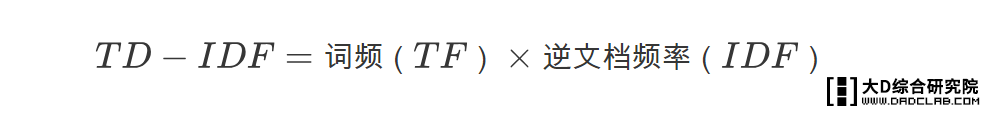
分词和分析这里直接使用jieba分词。
由于北方边陲某市某区在其官方网站上都找不全工作报告,而且只需统计2012-2019年这几年的(互联网上只找到这几年的数据),干脆就手动保存一下好了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import jieba from collections import Counter def cutText(text): """ 对一段文本进行分词,过滤掉长度小于2的词,jieba分词采用精确模式分词。 :param text: 文本 :return: 词 """ cutList = jieba.cut(text.lower(), cut_all=False) wordsArray = [] for word in cutList: if len(word) >= 2: wordsArray.append(word) return wordsArray |
|
1 2 3 4 5 6 7 8 9 10 |
def getTopnWords(text, topn): """ 统计出一段文本中出现最多的前n个关键词及数量 :param text: 文本 :param topn: 数量 :return: 数组 """ cutList = cutText(text) counter = Counter(cutList) return counter.most_common(topn) |
|
1 2 3 4 5 |
from cutTextUtils import getTopnWords if __name__ == "__main__": testStr = "新京报快讯(记者 陈沁涵)4月25日,第二届“一带一路”国际合作高峰论坛“设施联通”分论坛在北京举行。柬埔寨国务大臣兼公共工程和运输大臣孙占托在分论坛上发表讲话,他说,通过中国的帮助,柬埔寨已经开始建设国内第一条高速公路。中国的“一带一路”倡议为世界带来了繁荣。" print(getTopnWords(testStr, 5)) |
测试结果:
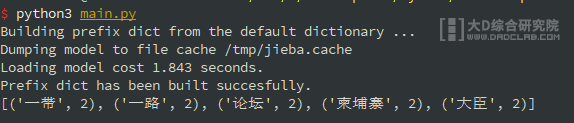
可以看到,关键词“一带一路”被分为了两个词(“一带”,“一路”),所以这里需要加载一下用户词典,用于提高分词准确率。
用户自定义词典加入“一带一路”一词。
修改后的cutText函数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def cutText(text): """ 对一段文本进行分词,过滤掉长度小于2的词,jieba分词采用精确模式分词。 :param text: 文本 :return: 词 """ jieba.load_userdict("userDict.txt") # 加载自定义词典 cutList = jieba.cut(text.lower(), cut_all=False) wordsArray = [] for word in cutList: if len(word) >= 2: wordsArray.append(word) return wordsArray |
加载后的测试结果:

现在加载一个保存好的ZF工作报告进行一下,提炼一下出现最多的词看看。
考虑到文件编码问题,处理一下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
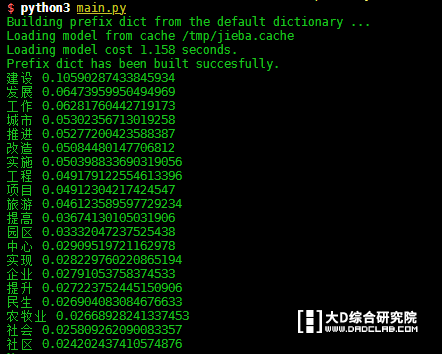
if __name__ == "__main__": # 处理文件编码 for encodeStr in ["utf-8", "gb18030", "gb2312", "gbk", "Error"]: try: fr = open("reportData/2012.txt", "r", encoding=encodeStr).read() break except: if encodeStr == "Error": raise Exception("file read error") continue print(getTopnWords(fr, 20)) |
结果如下:

可以看到,筛选出了很多意义不大的词汇,需要过滤一下。
新建一个停用词词典并写入若干停用词。
修改后的cutText函数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def cutText(text): """ 对一段文本进行分词,过滤掉长度小于2的词,jieba分词采用精确模式分词。 :param text: 文本 :return: 词 """ stopWord = [] stopWordFile = open("stopWordDict.txt", "r", encoding="utf-8").readlines() for line in stopWordFile: stopWord.append(line.split("\n")[0]) jieba.load_userdict("userDict.txt") # 加载自定义词典 cutList = jieba.cut(text.lower(), cut_all=False) wordsArray = [] for word in cutList: if len(word) >= 2: if(word not in stopWord): wordsArray.append(word) return wordsArray |
结果如下:

这里可以看到提取到了出现次数较多的关键字,接下来计算一下关键字频率。
jieba分词实现了TD-IDF算法和TextRank算法,直接使用即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from jieba.analyse import extract_tags from jieba.analyse import set_stop_words def frequency(text, topN): """ TD-IDF算法进行词频统计 :param text: 待统计文本 :return: 关键词及词频 """ # 加载停用词 set_stop_words("stopWordDict.txt") # 提取词频前N个的关键词存储到列表tags tags = extract_tags(sentence=text, topK=topN, withWeight=True) for item in tags: print(item[0], item[1]) |
结果如下:
创建词云使用wordcloud库。
由于wordcloud需要传入一个词与词之间使用空格分隔的字符串,所以分词之后,使用字符串的join方法将分词List内的词组合成字符串。
生成词云使用的图是作出被分析报告的某市某区的行政区划图,该图一般越清晰,生成词云效果越好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import wordcloud as wCloud from PIL import Image from numpy import array import matplotlib.pyplot as plt from cutTextUtils import cutText def wCloudImage(text, filename): """ 根据分词生成词云 :param text: 待分词文本 :param filename: 图文件名 :return: None """ # 分词 cutList = cutText(text) # 合并字符串 data = " ".join(cutList) # 加载字体 font = "wqy.ttf" # 打开图片并将图片转为数组 pic = Image.open("map.jpg") picArray = array(pic) # 生成词云 myImage = wCloud.WordCloud(collocations=False, font_path=font, mask=picArray, background_color="white").generate(data) # 设置画布大小 plt.figure(figsize=(10,10)) # 去掉坐标轴 plt.axis('off') # 显示并保存图片 plt.imshow(myImage) plt.savefig(filename + ".png") plt.show() |

通过词云还无法很直观的看出某一个关键字出现频次的水平,所以使用matplotlib来绘制一个条状图。
先将以计算频次的数据进行矩阵转置,分解成两个numpy.ndarray,其中的数据根据索引一一对应。
但矩阵转置后,第二组的numpy.ndarray中数字被转为了字符串格式,所以需要在后面加载数据时,转为数字。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
import numpy as npy import matplotlib.pyplot as plt import matplotlib.font_manager as fManager def histogram(wordData, title, filename): """ 创建柱状图 :param wordData: 分词统计后数据 :param title: 图标题 :param filename: 图文件名 :return: None """ # wordData转numpy数组并作矩阵转置 tmp = npy.array(wordData).T # 设置画布大小 fig,ax = plt.subplots(figsize=(10,10)) # 中文字体 font = fManager.FontProperties(fname="wqy.ttf") # 设置图表标题 plt.title(title, fontproperties=font, fontsize=20) # 设置x轴 ax.set_xlabel("出现次数", fontproperties=font, fontsize=20, color="black") # 调整图表四周框线颜色 ax.spines['bottom'].set_color("gray") ax.spines['left'].set_color("gray") ax.spines['top'].set_color("white") ax.spines['right'].set_color("white") # 设置x轴的值在0刻度 ax.spines['left'].set_position(('data', 0)) # 导入关键字数据,设置y轴显示标记位置,设置文字大小及颜色 ticksPositions = range(1, len(tmp[1]) + 1) ax.set_yticks(ticksPositions) # y轴数据反转一下,否则跟数据柱对不上 ax.set_yticklabels(tmp[0][::-1], fontproperties=font, fontsize=16, color="black") # 生成barh用的y参数数据(跟第二个参数的数据长度一致) barPositions = npy.arange(len(tmp[1])) + 1 # 导入关键字频次数据,设置对齐方式 ax.barh(barPositions, tmp[1][::-1].astype(int).tolist(), 0.5, align="center") plt.savefig(filename + ".png") plt.show() |
生成的条状图如下:

把这几年的文本合成为一个文本进行分析。对main.py进行一下修改。
主要是将多年的文件路径写入List,循环遍历每一个文件进行读取,并将文件内容合并,用于后续的操作。
其他部分的源码无需改变,只需在main.py中调用各部分函数即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
from cutTextUtils import getTopnWords from frequency import frequency from wordImg import wCloudImage from histogram import histogram if __name__ == "__main__": fr = "" filename = [ "reportData/2012.txt", "reportData/2013.txt", "reportData/2014.txt", "reportData/2015.txt", "reportData/2016.txt", "reportData/2017.txt", "reportData/2018.txt", "reportData/2019.txt", ] # 处理文件编码 for eachFile in filename: for encodeStr in ["utf-8", "gb18030", "gb2312", "gbk", "Error"]: try: fr += open(eachFile, "r", encoding=encodeStr).read() break except: if encodeStr == "Error": raise Exception("file read error") continue print("计算频次最高的30个关键字") for item in getTopnWords(fr, 30): print(item) print("=======================================") print("提取权重大的30个关键字") print(frequency(fr, 30)) print("=======================================") print("生成词云") wCloudImage(fr, "wclound1") print("=======================================") print("生成条状图") histogram(getTopnWords(fr, 30), "2012-2019年某市某区政府工作报告词频统计", "histogram") print("=======================================") print("执行完毕") |
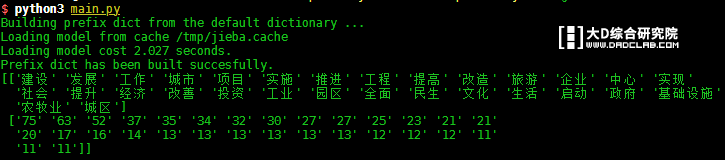
运行结果如下:

TD-IDF 提取关键字
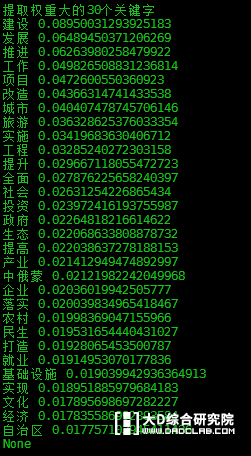
生成的词云和条状图


接下来就是重点了,分析自1954年以来的国务院政府工作报告。
已知1954-2017年的文本在中央的网站上是有一个专题的,网址如下:
http://www.gov.cn/guoqing/2006-02/16/content_2616810.htm
2017年公告全文网址:
http://www.gov.cn/premier/2017-03/16/content_5177940.htm
2018年公告全文网址:
http://www.gov.cn/zhuanti/2018lh/2018zfgzbg/zfgzbg.htm
2019年公告全文网址:
http://www.gov.cn/zhuanti/2019qglh/2019lhzfgzbg/index.htm
2017年报告是以专题形式呈现的,但2017年报告全文页的页面形式与2014-2016年的报告全文页面是一样的。
1954-2013年的报告全文页面基本可以认作是一样的。
2018、2019年两年虽然也是专题页面,但结构大体相似。
从侧面也反映了前端技术、UI设计理念的改变。
那么,根据三种不同的页面,需要制定三种不同的解析方式。
先创建一个共用的获取页面html的函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import requests # 设置headers HEADERS = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36" } def getHtml(url): """ 获取网页html :param url: 网页url :return: html文本 or None """ resp = requests.get(url, headers = HEADERS) if resp.encoding != "utf-8": resp.encoding = "utf-8" if resp: return resp.text return None |
获取全部的url
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from htmlUtils import getHtml from bs4 import BeautifulSoup as bs def getAllReportUrls(url): """ 获取每年的工作报告所在的网页url :param url: 汇总页面的Url :return: 所有的url组成的Dict """ reportUrls = {} allUrlHtmlSource = getHtml(url) # bs4 html解析器 soup = bs(allUrlHtmlSource, "html.parser") # 获取页面内url数据的表格 yearsTable = soup.select("#UCAP-CONTENT table tbody")[0] for itemTr in yearsTable.select("tr"): for itemTd in itemTr.select("td"): for itemA in itemTd.select("a"): # 加个判断过滤掉2017年的,因为是单独的专题页面 if itemA.text != "2017": reportUrls[itemA.text] = itemA.get("href") return reportUrls |
上面说道三种不同页面的情况,根据应用页面数量从多到少的考虑。
页面应用数量最多的就是表格形式布局的1954-2013年这段时间的,这些页面结构简单,没有其他的干扰,为了严谨一些,还是去抓取正文的内容。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def getReportText(url): """ 获取公告全文的文字内容 :param url: 全文网页连接 :return: 文本内容 """ html = getHtml(url) soup = bs(html, "html.parser") # 针对1954-2013年全文的抓取 article = soup.select(".p1") if len(article) == 0: # 针对2014-2017年全文的抓取 article = soup.select("#UCAP-CONTENT") if len(article) == 0: # 针对2018、2019年全文的抓取 article = soup.select(".zhj-bbqw-cont") if len(article) == 0: raise RuntimeError("抓取内容失败") return article[0].text |
分析
采集到所有的报告文字之后,只需要结合上面的代码,就可以得到关键字、关键字频次、词云和词频条状图了。
如果需要按照时间跨度来分片计算的话,搞一个List,以字符串形式存储年份即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
#!/usr/bin/python # -*- coding: utf-8 -*- # @Time : 2019/4/26 20:21 # @Author : Derek.S # @Site : # @File : gmain.py from bs4 import BeautifulSoup as bs from htmlUtils import getHtml from cutTextUtils import getTopnWords from frequency import frequency from wordImg import wCloudImage from histogram import histogram def getAllReportUrls(url): """ 获取每年的工作报告所在的网页url :param url: 汇总页面的Url :return: 所有的url组成的Dict """ reportUrls = {} html = getHtml(url) # bs4 html解析器 soup = bs(html, "html.parser") # 获取页面内url数据的表格 yearsTable = soup.select("#UCAP-CONTENT table tbody")[0] for itemTr in yearsTable.select("tr"): for itemTd in itemTr.select("td"): for itemA in itemTd.select("a"): # 加个判断过滤掉2017年的,因为是单独的专题页面 if itemA.text != "2017": reportUrls[itemA.text] = itemA.get("href") return reportUrls def getReportText(url): """ 获取公告全文的文字内容 :param url: 全文网页连接 :return: 文本内容 """ html = getHtml(url) soup = bs(html, "html.parser") # 针对1954-2013年全文的抓取 article = soup.select(".p1") if len(article) == 0: # 针对2014-2017年全文的抓取 article = soup.select("#UCAP-CONTENT") if len(article) == 0: # 针对2018、2019年全文的抓取 article = soup.select(".zhj-bbqw-cont") if len(article) == 0: raise RuntimeError("抓取内容失败") return article[0].text if __name__ == "__main__": content = "" urls = getAllReportUrls("http://www.gov.cn/guoqing/2006-02/16/content_2616810.htm") urls["2017"] = "http://www.gov.cn/premier/2017-03/16/content_5177940.htm" urls["2018"] = "http://www.gov.cn/zhuanti/2018lh/2018zfgzbg/zfgzbg.htm" urls["2019"] = "http://www.gov.cn/zhuanti/2019qglh/2019lhzfgzbg/index.htm" for itemUrl in urls: content += getReportText(urls[itemUrl]) print("计算频次最高的20个关键字") for item in getTopnWords(content, 20): print(str(item[0]) + ":" + str(item[1])) print("=======================================") print("提取权重大的20个关键字") print(frequency(content, 20)) print("=======================================") print("生成词云") wCloudImage(content, "1954-2019-wclound", "chinamap.jpg") print("=======================================") print("生成条状图") histogram(getTopnWords(content, 20), "1954-2019年政府工作报告词频统计", "1954-2019-histogram") print("=======================================") print("执行完毕") # 如果需要写入文件,使用以下代码 # f = open("report.txt", "a", encoding="utf-8") # f.write(content) # 如果需要按照时间跨度来分片计算的话,使用如下代码 # urls = getAllReportUrls("http://www.gov.cn/guoqing/2006-02/16/content_2616810.htm") # urls["2017"] = "http://www.gov.cn/premier/2017-03/16/content_5177940.htm" # urls["2018"] = "http://www.gov.cn/zhuanti/2018lh/2018zfgzbg/zfgzbg.htm" # urls["2019"] = "http://www.gov.cn/zhuanti/2019qglh/2019lhzfgzbg/index.htm" # # yearsOne = ["1954", "1955", "1956", "1957", "1958", "1959", "1960", "1964"] # yearsTwo = ["1975", "1978", "1979", "1980", "1981", "1982", "1983", "1984", "1985"] # yearsThree = ["1986", "1987", "1988", "1989", "1990", "1991", "1992", "1993", "1994", "1995", "1996"] # yearsFour = ["1997", "1998", "1999", "2000", "2001", "2002", "2003", "2004", "2005", "2006", "2007"] # yearsFive = ["2008", "2009", "2010", "2011", "2012", "2013", "2014", "2015", "2016", "2017", "2018", "2019"] # # yearsList = [yearsOne, yearsTwo, yearsThree, yearsFour, yearsFive] # # for years in yearsList: # content = "" # for year in years: # content += getReportText(urls[year]) # # yearInfo = years[0] + "-" + years[-1] # # print(yearInfo) # print("=======================================") # print("计算频次最高的20个关键字") # for item in getTopnWords(content, 20): # print(str(item[0]) + ":" + str(item[1])) # print("=======================================") # print("提取权重大的20个关键字") # print(frequency(content, 20)) # print("=======================================") # print("生成词云") # wCloudImage(content, yearInfo + "-wclound", "chinamap.jpg") # print("=======================================") # print("生成条状图") # histogram(getTopnWords(content, 20), yearInfo + "年政府工作报告词频统计", yearInfo + "-histogram") # print("=======================================") # print("执行完毕") |
结果
结果图片比较多,干脆合成到一张图上,图片较大(点击图片可以查看大图),请耐心等待。
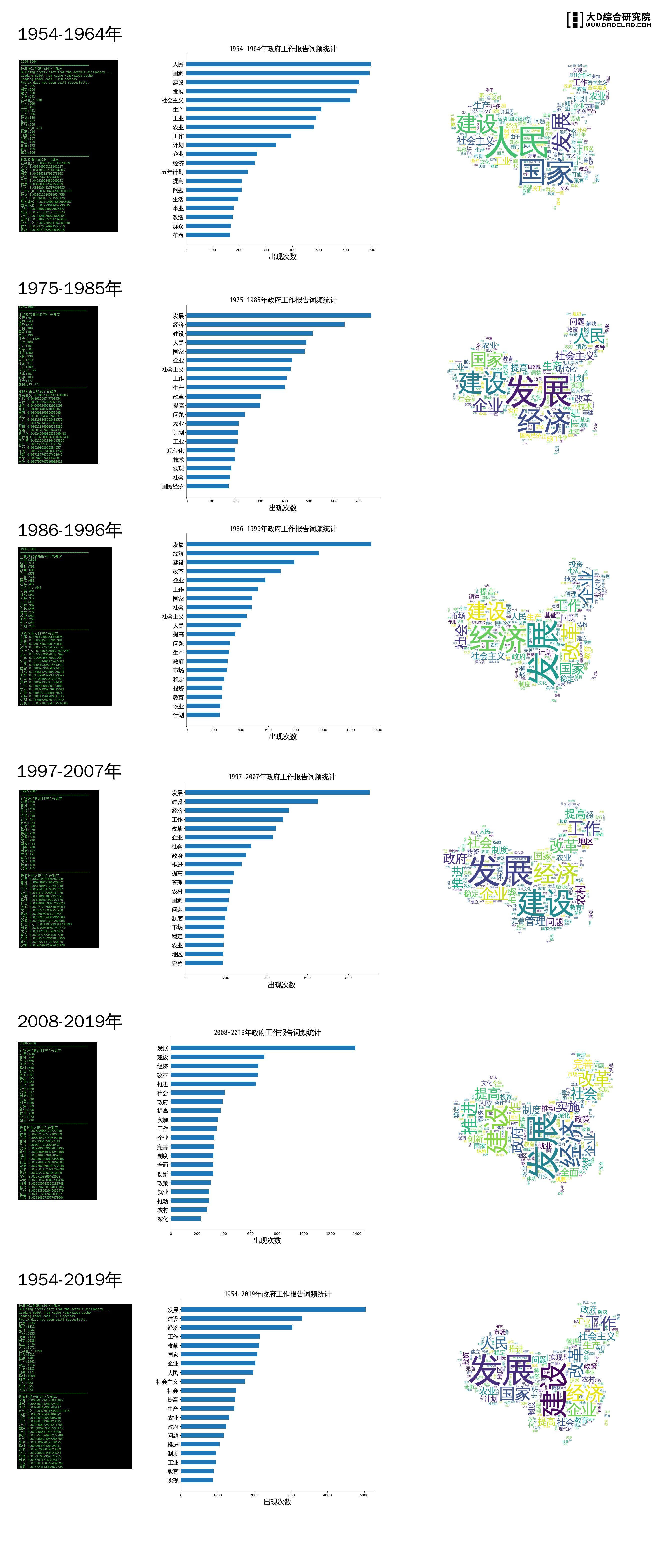
结论
发展才是硬道理!
Github
代码已开源,见:
https://github.com/derek-s/Python-GovWorkReportAnalyze
已有 1 条评论
发表评论
电子邮件地址不会被公开。 必填项已标注。
实力YM大D牛