用Python实现批量下载Flickr相册
背景故事
写这篇博文的时候,大D疑似感冒症状,思维迟钝。在本文有什么错误、错字之类的,欢迎在评论中指出~
回到正题,大D是一个伪·摄影爱好者,为啥说伪呢,因为没有几张拿的出手的照片。
购买单反一段时间之后,大D知道了一个叫做Flickr的网站,于是经常将自己的拙作上传到Flickr。但是众所周知,访问Flickr是一件有点难度的事情。是需要学习“科学上网”技能的,为此,大D在国内也寻找了大量的替代服务。比如图虫。
说到图虫,图虫其实真心不错,唯一觉得不够开心的就是图虫采用的是图博形式,虽然也能够单张发,但是总感觉没有Flickr便捷。
由于访问Flickr日渐困难,于是大D觉得需要将自己的相册备份一份出来,虽然电脑上也有备份,但是是散落在以日期为分类方式的一堆目录当中。纵然使用Photoshop Lightroom等软件进行管理,想完全整理出发到Flickr的版本还是有点困难。
所以还是备份吧。Google了一番,也有现成的软件,要么是收费的,要么是无法用的。
后来,在CSDN发现了这样一篇文章:使用FlickrDownloader批量下载Flickr的相册
在阅读之后,虚拟机上装了个Win8,跑起来,下载了一下之后发现,会将重名的掩盖掉,而不是重命名后存储。这对于大D这种从来不给片子起名字,直接按照文件名上传Flickr的人带来了一些不便。
思索一番之后,决定闭门造车,自己造个轱辘出来。
原理
其实这原理没什么好说的。。看了CSDN上的那篇文章之后,大D也采用了跟他一样的方式,就是提取网页源代码中的链接。
Flickr网页源代码中,会存在如下的代码:
|
1 |
Y.ContextData.add({"id":"photostream","type":"stream","title":"Derek.S_\u5927D Photostream","url":"\/photos\/derek-s\/","total":"263","prev_limit":0,"next_limit":262,"photos":[{"position":"0","photo":{"id":"16652307641","title":"DSC_0186","license":"0","safety_level":1,"owner":"96551909@N06","ownername":"Derek.S_\u5927D","pathalias":"derek-s","iconserver":"8128","iconfarm":9,"url":"\/photos\/derek-s\/16652307641\/in\/photostream","media":"photo","date_posted":"1424961367","date_taken":"2015-02-17 17:01:10","fave_count":"0","comment_count":"0","is_fave":false,"secret":"a8f813ac94","sizes":{"sq":{"label":"Square","file":"16652307641_a8f813ac94_s.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_s.jpg","width":75,"height":75},"q":{"label":"Large Square","file":"16652307641_a8f813ac94_q.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_q.jpg","width":"150","height":"150"},"t":{"label":"Thumbnail","file":"16652307641_a8f813ac94_t.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_t.jpg","width":"100","height":"67"},"s":{"label":"Small","file":"16652307641_a8f813ac94_m.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_m.jpg","width":"240","height":"161"},"n":{"label":"Small 320","file":"16652307641_a8f813ac94_n.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_n.jpg","width":"320","height":214},"m":{"label":"Medium","file":"16652307641_a8f813ac94.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94.jpg","width":"500","height":"334"},"z":{"label":"Medium 640","file":"16652307641_a8f813ac94_z.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_z.jpg","width":"640","height":"428"},"c":{"label":"Medium 800","file":"16652307641_a8f813ac94_c.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_c.jpg","width":"800","height":535},"l":{"label":"Large","file":"16652307641_a8f813ac94_b.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_a8f813ac94_b.jpg","width":"1024","height":"685"},"h":{"label":"Large 1600","file":"16652307641_7515588a89_h.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_7515588a89_h.jpg","width":"1600","height":1071},"k":{"label":"Large 2048","file":"16652307641_cf837efee6_k.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_cf837efee6_k.jpg","width":"2048","height":1371},"o":{"label":"Original","file":"16652307641_ff6d8a0649_o.jpg","url":"https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_ff6d8a0649_o.jpg","width":"3872","height":"2592"}},"woe":{"woeid":null}}}]}); |
该代码片段是重复出现的,从代码中可以看出完全尺寸(Original)的照片链接地址是如下形式的:
|
1 |
https:\/\/c1.staticflickr.com\/9\/8629\/16652307641_ff6d8a0649_o.jpg |
比对其他链接,会发现文件名结构上的"_o.jpg"是表示其尺寸的,在了解了连接形式之后,使用正则表达式匹配一下。
大D是不太会正则表达式的,每次都是现用现查文档,最后在使用正则表达式测试器来测试。所以大D整理出的正则表达式可能不是最优的表达式组合。
匹配正则表达式如下:
|
1 |
[a-z]+:+\\+\/+\\+\/\w*.\w*.\w*.\/\d\\\/\d*\\\/\d*\w{12}[o].[jpg]* |
基本上方法就是匹配连接,去除连接中多余的\,然后下载这些链接就可以了。
这个小玩意儿就是大D自己用的,文件名处理什么的完全没考虑,直接用链接中的文件名就好了。
实现
首先自然是读入源代码文件,正则表达式匹配链接然后存储到临时文件当中去。
|
1 2 3 4 5 6 7 8 9 |
f = open('/home/Derek.S/py/1.html') restr = r'[a-z]+:+\\+\/+\\+\/\w*.\w*.\w*.\/\d\\\/\d*\\\/\d*\w{12}[o].[jpg]*' url = f.read() strlist = re.findall(restr,url) f.close f = open(r'temp.txt','a') for i in range(0,len(strlist)): f.write(strlist[i]+"\n") f.close |
在正则表达式的r是原始字符串符号,我们需要正则表达式这个字符串不会被转义。
接下来要做的就是去除多余的"\"
|
1 2 3 |
urlrestr = r'\/' urlist = re.sub(urlrestr,"",urlstr[x]) down = urlist.replace("\\","/") |
取文件名操作并指定工作目录
|
1 2 3 4 |
local_file = down.split('/')[-1] filename = local_file.split('.')[0] local_dir = '/home/Derek.S/Flickr/' down_dir = str(local_dir) + str(filename)+".jpg" |
下载去重以及下载部分:
|
1 2 3 4 5 6 |
if os.path.exists(down_dir) == True: print ("-----Pic already exists-----") elif os.path.exists(down_dir) == False: r = requests.get(down, verify=False) with open(down_dir, "wb") as code: code.write(r.content) |
最后跑起来如下图:

遇到的问题
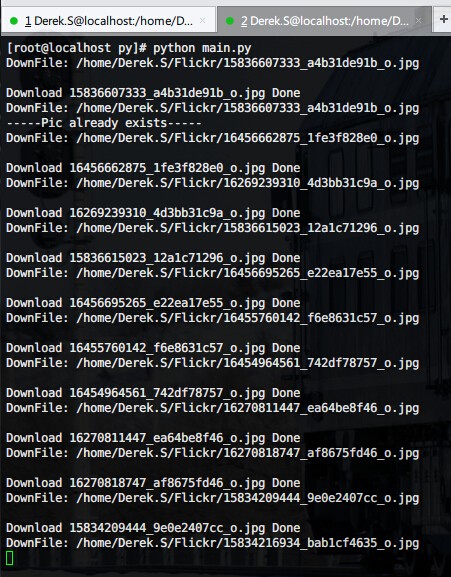
1.由于网络的问题,可能会下载到只有一半的照片,这时候就只能根据文件名自己动手重新下载一个。
2.Flickr采用了https,下载时会遇到https ssl认证的问题,Google了许久没有找到合适的解决方法,也看了urllib3的文档,也没有解决,最后只好通过关闭警告的方式来解决了。
|
1 2 |
urllib3.disable_warnings() requests.packages.urllib3.disable_warnings() |
3.对于文件名,应该有更好的处理办法。
完整源代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
#coding:UTF-8 _author_ = 'Derek.S' import string import codecs import re import os import urllib import requests import ssl import urllib3 urllib3.disable_warnings() requests.packages.urllib3.disable_warnings() verify='/etc/ssl/certs/ca-certificates.crt' #url string f = open('/home/Derek.S/py/1.html') restr = r'[a-z]+:+\\+\/+\\+\/\w*.\w*.\w*.\/\d\\\/\d*\\\/\d*\w{12}[o].[jpg]*' url = f.read() strlist = re.findall(restr,url) f.close f = open(r'temp.txt','a') for i in range(0,len(strlist)): f.write(strlist[i]+"\n") f.close rows = str( len(strlist) ) url = open('url.txt','a') f = open('temp.txt','r') urlstr = f.readlines() urlrestr = r'\/' for x in range(0,len(urlstr)): urlist = re.sub(urlrestr,"",urlstr[x]) down = urlist.replace("\\","/") local_file = down.split('/')[-1] filename = local_file.split('.')[0] local_dir = '/home/Derek.S/Flickr/' down_dir = str(local_dir) + str(filename)+".jpg" url.write(down+"\n") print ("DownFile: " + down_dir) if os.path.exists(down_dir) == True: print ("-----Pic already exists-----") elif os.path.exists(down_dir) == False: r = requests.get(down, verify=False) with open(down_dir, "wb") as code: code.write(r.content) print('\nDownload ' +filename+".jpg"+" Done") f.close url.close |
也可以在Github上查看:https://github.com/derek-s/FlickrDownleader/blob/master/main.py
使用方法
使用方法什么的。。
这个脚本是运行在Linux上的,需要的就是打开需要下载的Flickr页面,右键空白处,查看源代码。
将源代码存储,然后修改Python源码中的:
|
1 |
f = open('/home/Derek.S/py/1.html') |
将/home/Derek.S/py/1.html修改为自己的路径和文件名。
同样将:
|
1 |
local_dir = '/home/Derek.S/Flickr/' |
修改为自己的目录就可以,然后需要的就是执行:
|
1 |
python main.py |
模块的问题就自己解决吧。
结尾
这只类爬虫是大D边查Python手册边Google出来的东西,在通用性上可能差强人意。
顺便一提,Python好好用。
难受惨了。睡觉。
已有 4 条评论
发表评论
电子邮件地址不会被公开。 必填项已标注。
万能的大D
@adamfei 好久不见哇~~一点都不万能。嘿嘿。
门外汉表示想用,但是下了phython安装好了关联了打开它并没有跑起来,怎么才能让它跑起来呢? windows系统 求教
是不是f = open('C:\Users\Public\Desktop\1.html')我指定的路径不对呢?
@jequery 您好,如果运行有错误,会有一些提示的。其次,现在Flickr有了官方的工具,叫做Flickr uploader,可以用来管理您的照片,也可以用于下载您存储在Flickr上的照片的。安装好工具并登陆之后可以进入相机胶卷,然后就可以选择照片进行下载了。本文的方法可能不适用改版后的flickr了。